Verification and Validation of Models - Invited Lectures Series - 3
The third invited lecture for the new verification and validation of models course is on Monday (Oct 19, 2020) at 7:20 PM EST. This week, Dr. Bilal Kartal, Founder in Residence at Entrepreneur First, will give a lecture titled “Safer Deep Reinforcement Learning and Auxiliary Tasks”. If you’re interested in joining the lecture, please email me (see the flyer below) to receive the Zoom invitation link.

Lecture summary:
Safe reinforcement learning has many variants, and it is still an open research problem. In this talk, I describe different auxiliary tasks that improve learning and focus on using action guidance through a non-expert demonstrator to avoid catastrophic events in a domain with sparse, delayed, and deceptive rewards: the previously proposed multi-agent benchmark of Pommerman. I present a framework where a non-expert simulated demonstrator, e.g., planning algorithms such as Monte Carlo tree search with a small number of rollouts, can be integrated into asynchronous distributed deep reinforcement learning methods. Compared to vanilla deep RL algorithms, our proposed methods both learn faster and converge to better policies on a two-player mini version of the Pommerman game and Atari games.
Verification and Validation of Models - Invited Lectures Series - 2
The second invited lecture for the new verification and validation of models course is this coming Monday (Oct 12, 2020) at 7:20 PM EST with Dr. William (Bill) Kennedy from GMU. Dr Kennedy will give a lecture titled “Verification and Validation within Cognitive Modeling of Individuals”. If you’re interested in joining the lecture, please email me (see the flyer below) to receive the Zoom invitation link.

Lecture summary:
This presentation will be on the practice of V&V within the field of Cognitive Science and in particular Cognitive Modeling within Cognitive Science. The presentation will start with a demonstration of a cognitive phenomenon and a cognitive model of the human cognition behind it. Cognitive modeling will be introduced along with its relation to Artificial Intelligence. The practice of V&V in cognitive modeling relies on cognitive architectures and multiple lines of reasoning to support its models. The application of V&V to the ACT-R cognitive architecture and a specific cognitive model of intuitive learning will be discussed.
Verification and Validation of Models - Invited Lectures Series - 1
The Fall semester is in its full course and we are starting the first invited lecture for the new verification and validation of models course. Dr. Christopher J. Lynch from VMASC will give a lecture on Feedback-Driven Runtime Verification on Monday (Sep 21) at 7:20 PM EST. If you’re interested in joining the lecture, please email me (see the flyer below) to receive the invitation link.

Lecture summary:
Runtime verification facilitates error identification during individual simulation runs to increase confidence, credibility, and trust. Existing approaches effectively convey history, state information, and flow-of-control information. These approaches are common in practice due to shallow learning curves, lower mathematical requirements, and interpretation aided by observable feedback that provides context to the time and location of an error. However, runtime techniques lack consistent representation of the models’ requirements and the attention-demanding process of monitoring the run to identify and interpret errors falls on the user. As a result, these techniques lack consistent interpretation, do not scale well, and are time intensive for identifying errors.
To address these shortcomings, the lightweight, feedback-driven runtime verification (LFV) provides a formal specification that facilitates clear and consistent mappings between model components, simulation specifications, and observable feedback. These mappings are defined by simulation users, without requiring knowledge in formal mathematics, using the information available to them about how they expect a simulation to operate. Users specify values to simulation components’ properties to represent acceptable operating conditions and assign feedback to represent any violations. Any violations within a run trigger the corresponding feedback and direct users’ attention toward the appropriate simulation location while tracing back to the assigned specification. A formal specification adds transparency to error specification, objectiveness to evaluation, and traceability to outcomes. A two-group randomized experiment reveals a statistically significant increase in precision (i.e., the proportion of correctly identified errors out of the total errors identified) and recall (i.e., the proportion of correctly identified errors out of the total errors present) for participants’ using the LFV. The LFV opens new research areas for runtime verification of large-scale and hybrid simulations, occluded simulation components, and exploring the role of different feedback mediums in support of verification.
This lecture provides a brief historical background on Runtime Verification in M&S, an overview of the LFV to address existing shortcomings, and provides hands-on examples with implementing and interpreting runtime verification using the LFV of Discrete Event Simulations. You are encouraged to create an account with the CLOUDES simulation platform so that you can participate in the hands-on portion of the lecture. Accounts can be created at https://beta.cloudes.me/.
New verification and validation of models course at GMU

Now that data science (or as some call AI) has become very popular and modeling and simulation is getting a lot of attention (see companies like HASH), it is the right time to think about how to make these technologies even more rigorous and avoid potential misuses that have been surfacing lately. Verification and validation (V&V) is perhaps one of the first methodological practices when it comes to developing data science or simulation models. Verification usually refers to checking the correctness of the code, while validation refers to checking the correspondence between model results and expected results. These loose definitions are not sufficient, and, based on my anecdotal experience, the V&V process is often overlooked or blindly conducted. As a researcher who contributes to both data science and modeling and simulation, I find it very critical to discuss potential challenges and pitfalls of such models with the new generation researchers. Therefore, I am offering a new graduate-level class called Verification and Validation of Models this Fall to discuss such issues. The course is cross-listed in the Computational Science and Informatics (CSI) and the Computational Social Science (CSS) programs at GMU. Check out course description below:
Verification and Validation of Models (CSI 709/CSS 739)
Semesters offered: Fall 2020 (Online)
Computational models come in different forms ranging from machine learning models that predict/classify patterns to agent-based models that investigate emergent phenomena from a bottom-up perspective. Regardless of their form, all computational models should go through the Verification and Validation (V&V) process, which checks the correctness of the model design and performance. The proliferation of high-level frameworks and tools make it possible to bypass or overlook such steps. This graduate-level course aims to teach and improve V&V practices, which is considered as an essential methodological step in model development. Some of the topics include terminology and history of V&V, statistics for V&V, verification techniques, validation techniques, validation of data-driven models, and validation in the absence of data, among many others. Students will further their knowledge with writing assignments and a term project.
Leveraging agent-based simulation for prescriptive analytics of disease spread
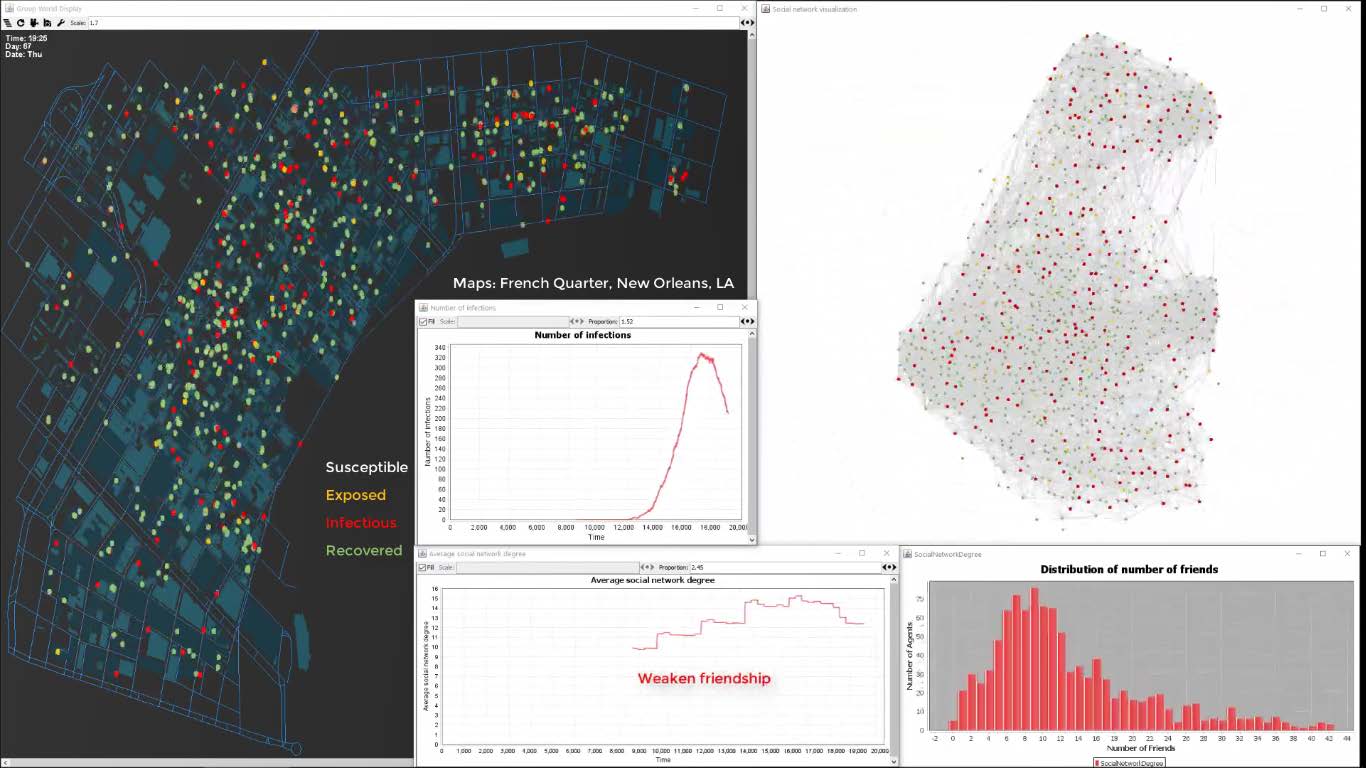
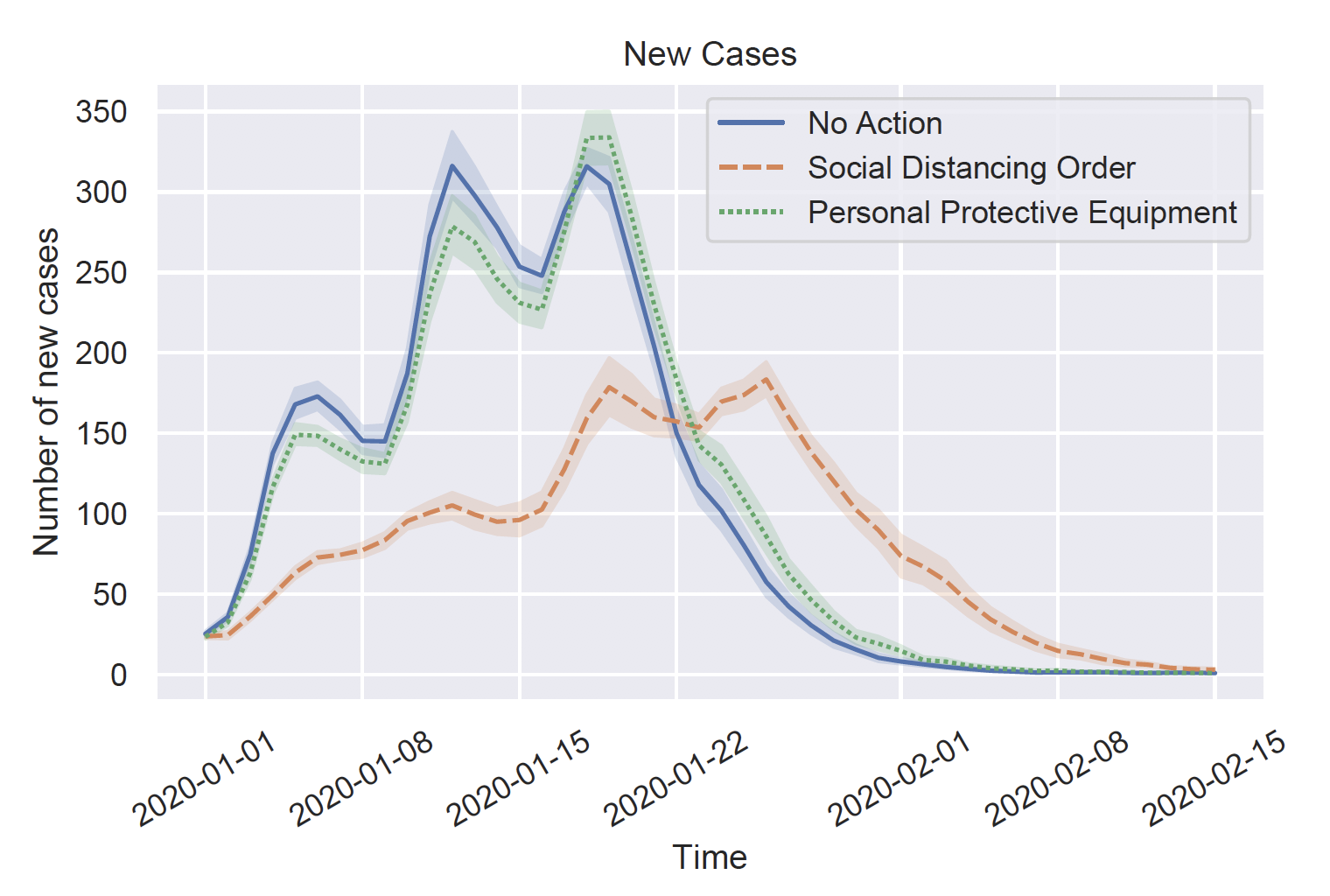
Large location-based social network (LSBN) data sets are indispensable to study complex human phenomena that involve both physical mobility and social interactions. Unfortunately, such large data sets are rare for researchers because businesses that collect such data use them to improve their operations and make a profit. In this recent SIGSPATIAL Special article, we presented our LBSN simulation framework that generates synthetic LSBN data and used it for prescriptive analytics of disease spread. Our simulation framework implements a socially plausible agent-based model to make the dataset realistic. We referenced both our synthetic data generator and related disease spread model in the paper. You can take a look at the abstract and access the paper freely using the reference below.
Abstract
Human mobility and social networks have received considerable attention from researchers in recent years. What has been sorely missing is a comprehensive data set that not only addresses geometric movement patterns derived from trajectories, but also provides social networks and causal links as to why movement happens in the first place. To some extent, this challenge is addressed by studying location-based social networks (LBSNs). However, the scope of real-world LBSN data sets is constrained by privacy concerns, a lack of authoritative ground-truth, their sparsity, and small size. To overcome these issues we have infused a novel geographically explicit agent-based simulation framework to simulate human behavior and to create synthetic but realistic LBSN data based on human patterns-of-life (i.e., a geo-social simulation). Such data not only captures the location of users over time, but also their motivation, and interactions via temporal social networks. We have open sourced our framework and released a set of large data sets for the SIGSPATIAL community. In order to showcase the versatility of our simulation framework, we added disease a model that simulates an outbreak and allows us to test different policy measures such as implementing mandatory mask use and various social distancing measures. The produced data sets are massive and allow us to capture 100% of the (simulated) population over time without any data uncertainty, privacy-related concerns, or incompleteness. It allows researchers to see the (simulated) world through the lens of an omniscient entity having perfect data.
Reference
Location-Based Social Simulation for Prescriptive Analytics of Disease Spread
J-S Kim, H. Kavak, C.O. Rouly, H. Jin, A. Crooks, D. Pfoser, C. Wenk, and A. Züfle
SIGSPATIAL Special, Volume 12 Issue 1, doi:10.1145/3292390.3292397
[Paper]
How can we model the modeler?
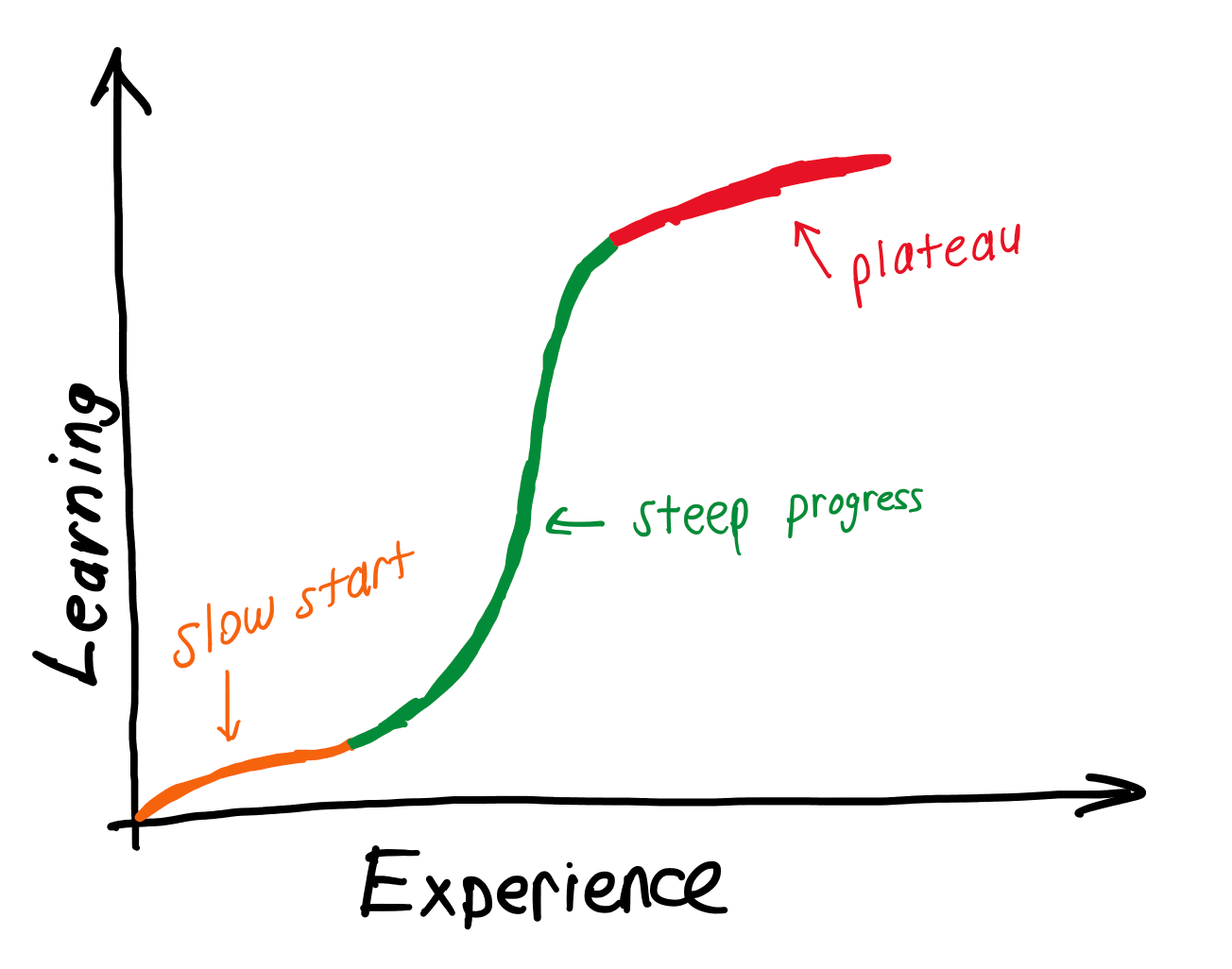
Every semester in my introductory class, I have new students who are interested in learning about modeling and simulation. One idea that struck me and my colleagues at VMASC was understanding the learning progress of these learners without bothering them with tests or labor-intensive assessments. We have our new paper presented at the 2020 Spring Simulation Conference that tackled this very challenge from an empirical perspective. Check out the presentation video, take a look at the abstract, or access our paper below. Let me know if you have any feedback.
Watch the presentation video on YouTube: https://youtu.be/eti0zj1mOQA
Abstract
This paper presents our novel efforts on automatically capturing and analyzing user data from a discrete-event simulation environment. We collected action data such as adding/removing blocks and running a model that enable creating calculated data fields and examining their relations across expertise groups. We found that beginner-level users use more blocks/edges and make more build errors compared to intermediate-level users. When examining the users with higher expertise, we note differences related to time spent in the tool, which could be linked to user engagement. The model running failure of beginner-level users may suggest a trial and error approach to building a model rather than an established process. Our study opens a critical line of inquiry focused on user engagement instead of process establishment, which is the current focus in the community. In addition to these findings, we report other potential uses of such user action data and lessons learned.
Reference
Modeling the Modeler: an Empirical Study on How Modelers Learn to Create Simulations
H. Kavak, J.J. Padilla, S.Y. Diallo and A. Barraco
The 2020 Spring Simulation Conference, Virtual, May 18-21, 2020
Paper
Exploring challenges in simulation verification
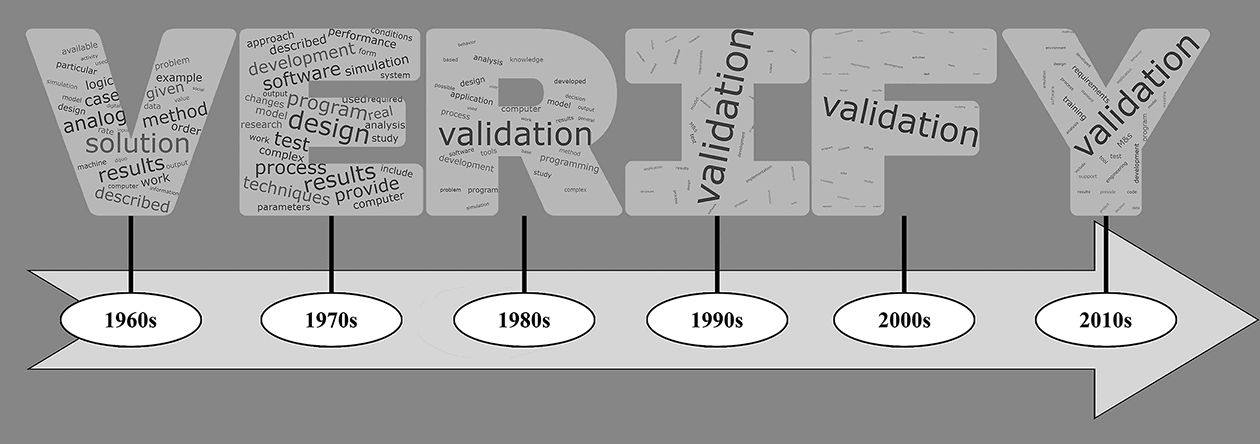
With simulations constantly receiving attention to support decisions and develop strategies in response to events such as the ongoing COVID-19 pandemic, people frequently ask how they can be expected to trust findings obtained from a simulation. Many factors play into the question of credibility including model assumptions, the use of data, calibration, to name a few. Many people don’t generally know how a simulation is expected to work, i.e. characteristics of COVID-19 spreads, or how to properly interpret the outcomes. To address such concerns, simulation modelers refer to the verification and validation (V&V) of models.
To explore the first V of V&V, my collaborators at Old Dominion University’s Virginia Modeling, Analysis and Simulation Center and myself have published a PLOS ONE article that presents our exploratory content analysis using over 4,000 simulation papers published from 1963-2015. See the abstract and reference below for details.
Abstract
Verification is a crucial process to facilitate the identification and removal of errors within simulations. This study explores semantic changes to the concept of simulation verification over the past six decades using a data-supported, automated content analysis approach. We collect and utilize a corpus of 4,047 peer-reviewed Modeling and Simulation (M&S) publications dealing with a wide range of studies of simulation verification from 1963 to 2015. We group the selected papers by decade of publication to provide insights and explore the corpus from four perspectives: (i) the positioning of prominent concepts across the corpus as a whole; (ii) a comparison of the prominence of verification, validation, and Verification and Validation (V&V) as separate concepts; (iii) the positioning of the concepts specifically associated with verification; and (iv) an evaluation of verification’s defining characteristics within each decade. Our analysis reveals unique characterizations of verification in each decade. The insights gathered helped to identify and discuss three categories of verification challenges as avenues of future research, awareness, and understanding for researchers, students, and practitioners. These categories include conveying confidence and maintaining ease of use; techniques’ coverage abilities for handling increasing simulation complexities; and new ways to provide error feedback to model users.
Reference
A content analysis-based approach to explore simulation verification and identify its current challenges
C.J. Lynch, S.Y. Diallo, H. Kavak, J.J. Padilla
PLOS One, 2020, doi:10.1371/journal.pone.0232929
[Paper]
The 2020 Spring Simulation Conference program is online

We are just ten days away from the 2020 Spring Simulation Conference. As the Program Chair of the conference, I am excited to tell you that we have an outstanding program, even though we had to shift all face-to-face events into a virtual setting. The conference will feature five tutorial sessions, one DEVS dissertation awards session, one demo session, eighteen regular paper + panel sessions covering 71 peer-reviewed papers. You can take a look at the details of the program here. It is still not too late to register and participate in the conference. Never been at SpringSim before? Contact me for a free invitation. The conference has some slots for first-time, non-author participants.
Simulation verification and validation as a service
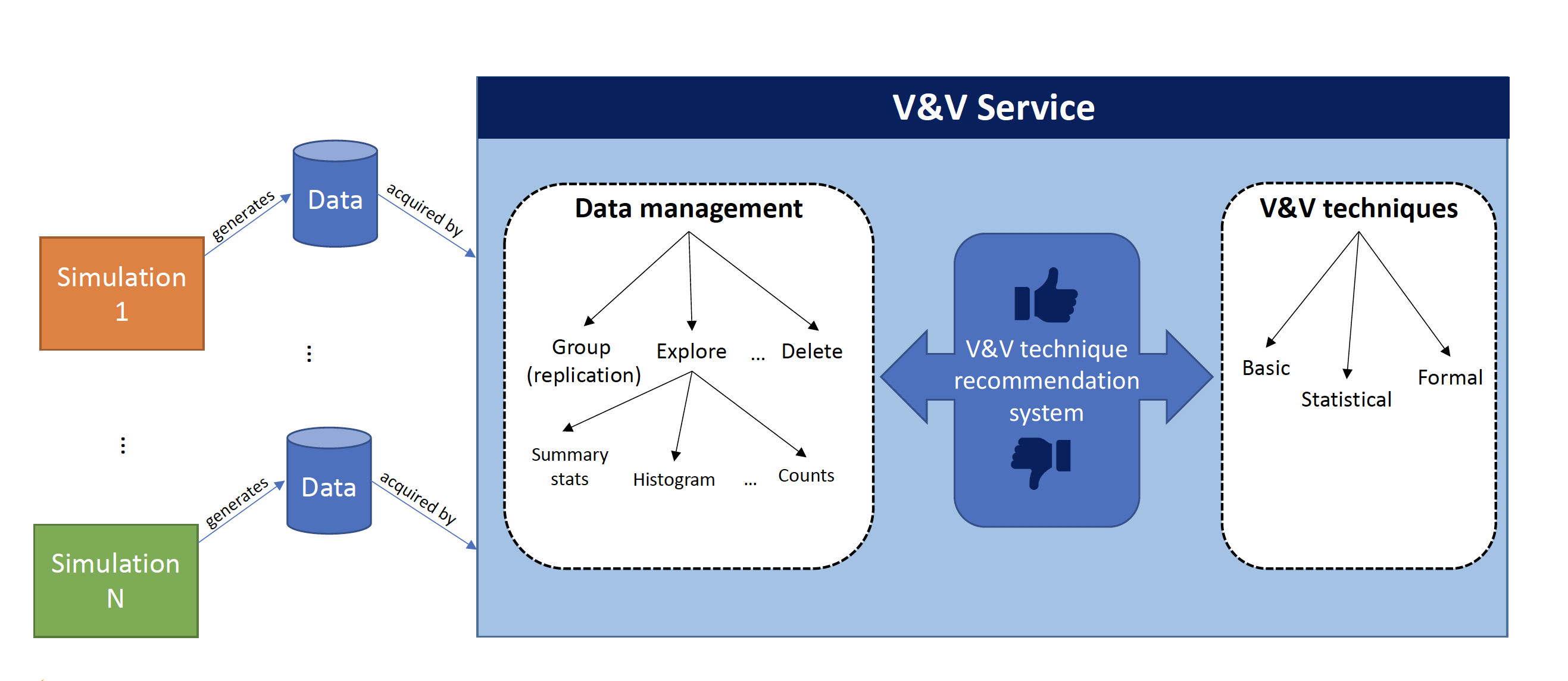
Verification and Validation (V&V) is one of the main processes in simulation development and is essential for increasing the credibility of simulations. Due to the extensive time requirement and the lack of common V&V practices, simulation projects often conduct ad-hoc V&V checks using informal methods. On Feb 7, 2020, I gave a talk in my department to discuss the building blocks of a new Verification and Validation platform, which can be utilized Software as a Service. This work-in-progress platform aims to improve V&V practices by facilitating ease of use, increasing accessibility to V&V techniques, and establishing independence from simulation paradigm and programming language. The platform relies on the seamless integration of web technologies, data management, discovery & analysis techniques of (V&V), and cloud computing. In the talk, I described the technical details of this platform, present a proof-of-concept implementation, and draw a roadmap for future developments.
If you are curious, here are the slides from my talk.
Spring Simulation Conference deadline approaching
It is that time of the year again! Spring Simulation Conference 2020 is around the corner. This time, the conference will be hosted by my institution, George Mason University. If interested in submitting a paper, the deadline is January 22, 2020. Accepted papers will be archived in the IEEE and ACM Digital Libraries.


