CCI Project Ended
![]()
Our project, funded by the Commonwealth Cyber Initiative, to support research efforts to curb the spread of misinformation and combat disinformation has officially ended today. Over the course of this project, conducted in collaboration with Dr. Saltuk Karahan from Old Dominion University, we analyzed anti-American disinformation and misinformation efforts on social media and in mass media. This project was funded in July 2021 and concluded in March 2023, resulting in four research papers that showcase our findings and methodological advancements.
Through our system development, we conducted sentiment and emotion analyses on Turkish social media content from X (twitter), identifying dominant negative emotions like disgust and anger in tweets related to the U.S. This helped us map out key periods and triggers for anti-American sentiment in Turkey. One study even focused on Turkey’s purchase of the Russian S-400 missile system, revealing how disinformation and political narratives are constructed to amplify nationalist sentiment and anti-American views. Another major outcome was our system’s capability to detect mass media disinformation, which allowed us to trace sentiment shifts and influence campaigns orchestrated through Turkish news outlets.
A critical element in these papers was the contributions of undergraduate students from George Mason University, whose hard work in data collection, machine learning model development, and analysis was invaluable. Their dedication enriched this research, showcasing the impressive capabilities that undergraduate researchers can bring to high-impact cybersecurity and disinformation studies. You can more about findings of this project here.
PhyloView
I’m excited to share PhyloView, a tool that our team at George Mason University together with David Attaway from ESRI have been working on to bring a new level of insight to understanding how infectious diseases like COVID-19 evolve and spread. PhyloView was developed to harness the vast amounts of phylogenetic and location-based data available on platforms like GISAID, which track genetic sequences of viruses from around the world. Built using ArcGIS Insights, PhyloView allows users to map the transmission paths of a virus over time and across different regions. This work was recently accepted to appear at the 23rd IEEE International Conference on Mobile Data Management (MDM). We will showcase PhyloView’s potential as a valuable tool for public health officials, researchers, and others interested in the complex dynamics of disease ecology.
One of the features I’m particularly excited about is how PhyloView brings multiple types of data together in a single, interactive dashboard. As shown in figure below, users can explore the disease data in several ways: a map that shows geographic spread, a phylogenetic tree that traces viral evolution, and a network visualization of how different strains of the virus are related and spread. These panels are fully interactive, meaning that selecting a case in one panel immediately updates the others. This cross-filtering feature lets users, for instance, zoom into a specific region or a single strain and watch the virus’s spread through that local network over time. Our hope is that this dynamic view will support local health departments in quickly identifying potential transmission hotspots, emerging strains, and important pathways of disease spread.
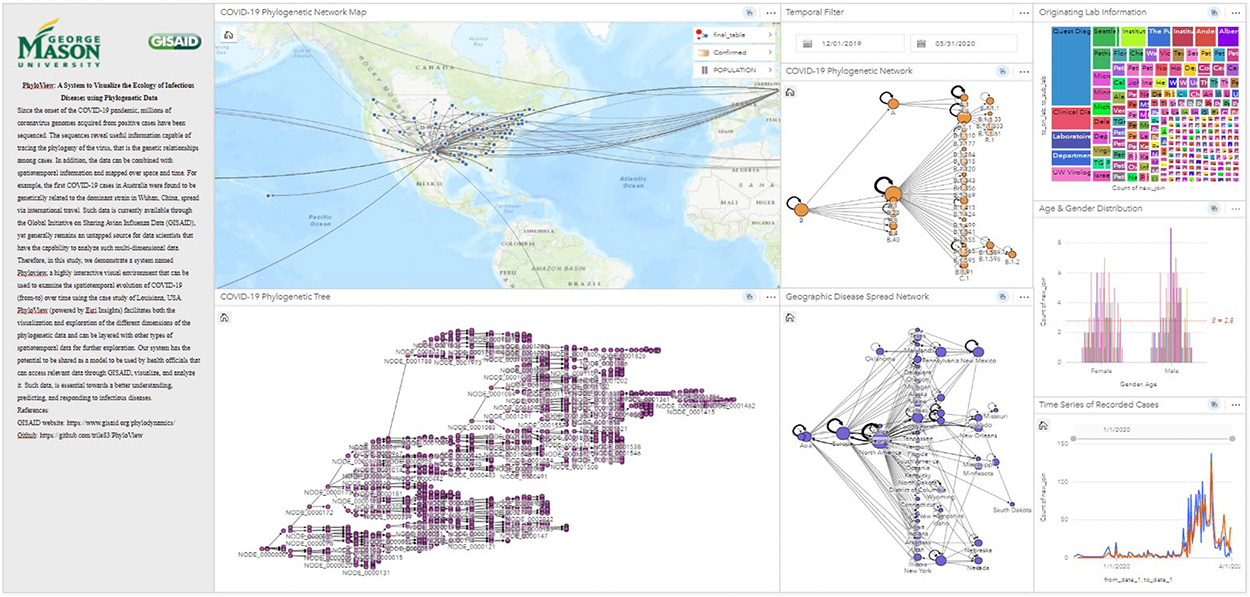
Our aim is that PhyloView will help not only during the current COVID-19 pandemic but also be adaptable to other infectious diseases in the future, allowing us to apply what we’ve learned to better protect communities. One particular tangent we are interested in is to integrate genetic mutations and variants in our data-driven disease models to advance the state-of-the-art.
You can access the paper here.
Dean's Award for Early Career Excellence
I am honored to have been selected for the 2021 Dean’s Award for Early Career Excellence from George Mason University’s College of Science. The Dean’s Awards recognize early-career faculty already making a significant impact in their field, enhancing their department and college profile through teaching and research excellence. I am grateful for this recognition and remain committed to my scholarship and to the success of my students.

Urban Life Model
About a year ago, our DARPA-funded Ground Truth Project ended while we continued reporting project outcomes. Today, our last paper from the project went online. Reflecting on this occasion, I feel grateful to have been part of such a unique project. Working alongside a team of established researchers and project leads like Andreas Züfle, Carola Wenk, Dieter Pfoser, Andrew Crooks, and many more has helped me grow as a researcher. This project made me delve deeper into agent-based simulations and the intricate dynamics of urban life, pushing the boundaries of what simulations can reveal about human behavior. The perseverance of our team in overcoming complex modeling challenges and eventually finding creative solutions will resonate with me throughout my career.

Through countless iterations, brainstorming meetings, and collaborative research, I have gained invaluable experience improving my analytical rigor and technical expertise in modeling. Moreover, this project helped me cultivate a more nuanced understanding of social dynamics. Each collaborator brought distinctive expertise that shaped the project’s success, from advancing scalability methods to crafting unique agent behaviors.
Finally, I want to thank everyone involved in this journey. The experiences, lessons, and friendships forged through this project are invaluable, reminding me that our field’s advancements rely on individual achievement and the strength of collaboration and collective passion. While I personally express a bitter farewell to this project, I am sure the experience and the models developed throughout this project will open new doors for our entire team in the future.
You can access the final paper here and source code here. To learn more details about the project, visit this page.
Human Mobility Change During COVID-19 in US (New Paper!)

How did human mobility patterns in the U.S. shift in response to COVID-19, and what factors drove these changes? Which regions showed the strongest adherence to mobility reductions, and how did political and economic factors shape these responses? Through unique metrics and spatial analysis of human footprint data, our recently published PLOS One article reveals compelling insights into the interplay between public behavior and policy during a pandemic. You can take a look at these findings in more detail in our paper here.
Foot Traffic Prediction (New Paper!)
In our recent paper called “Spatiotemporal Prediction of Foot Traffic,” we developed and tested a series of models to predict human movement patterns to various points of interest (POIs). We used large-scale mobility data from SafeGraph, which provides granular details on foot traffic across the United States, overcoming limitations common in traditional datasets that capture only sparse visit data. Our study aimed to forecast weekly visits to locations like stores and restaurants. This information holds significant applications for epidemiology, marketing, resource allocation, and urban planning.
We organized the data into a three-dimensional structure, or tensor, which captures the relationship between POIs, geographic regions (census block groups), and time. To filter out noise, we applied a collaborative filtering technique called tensor factorization, which enhances the predictive accuracy by focusing on latent patterns within the data. The study tested several forecasting methods, including simple average models, linear and polynomial regression, and long short-term memory (LSTM) neural networks. Notably, simpler models, like a weighted average of recent visits, often outperformed more complex models, highlighting that a basic temporal approach can yield reliable forecasts when paired with collaborative filtering (as shown in Figures 1 and 2 below).
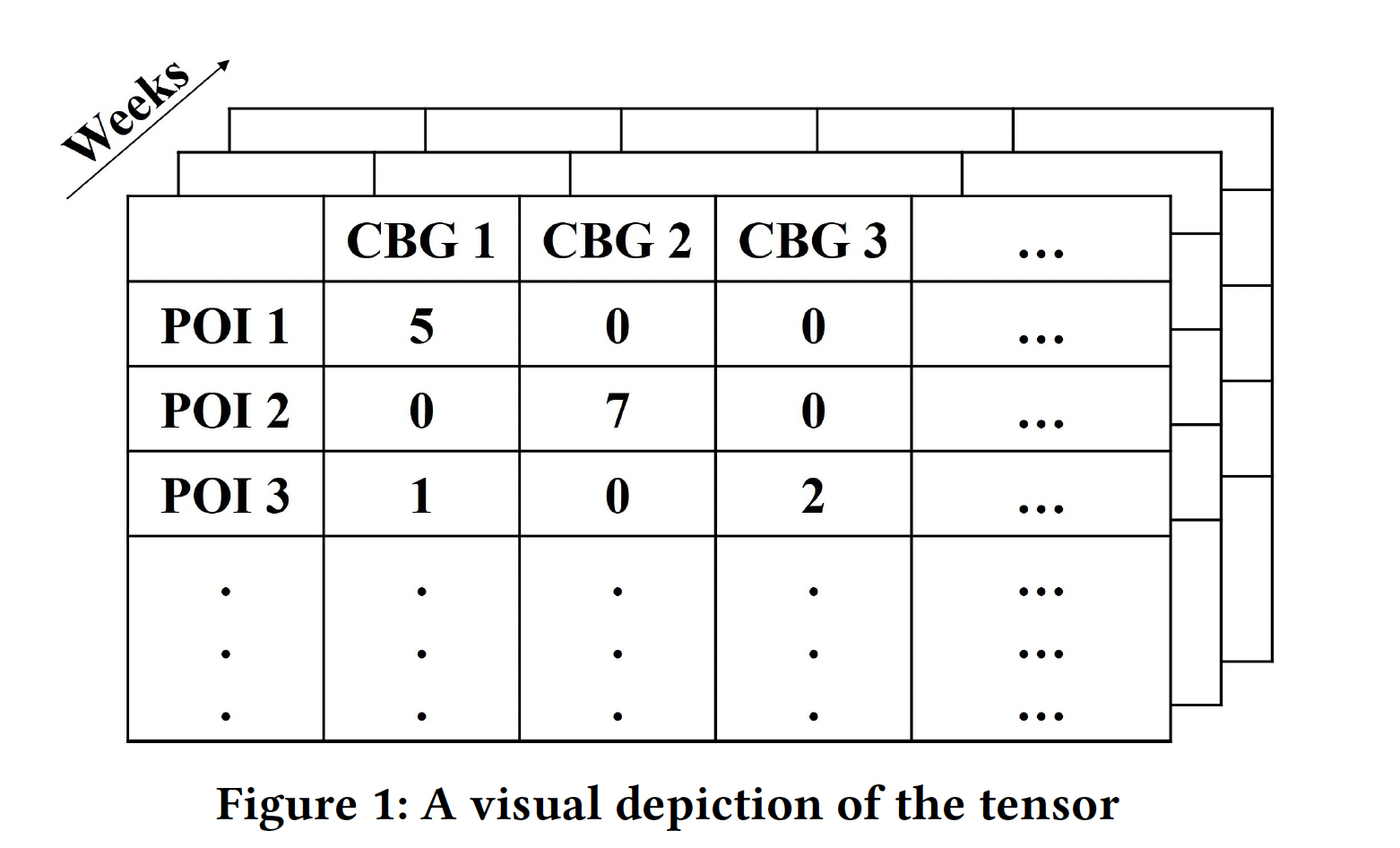
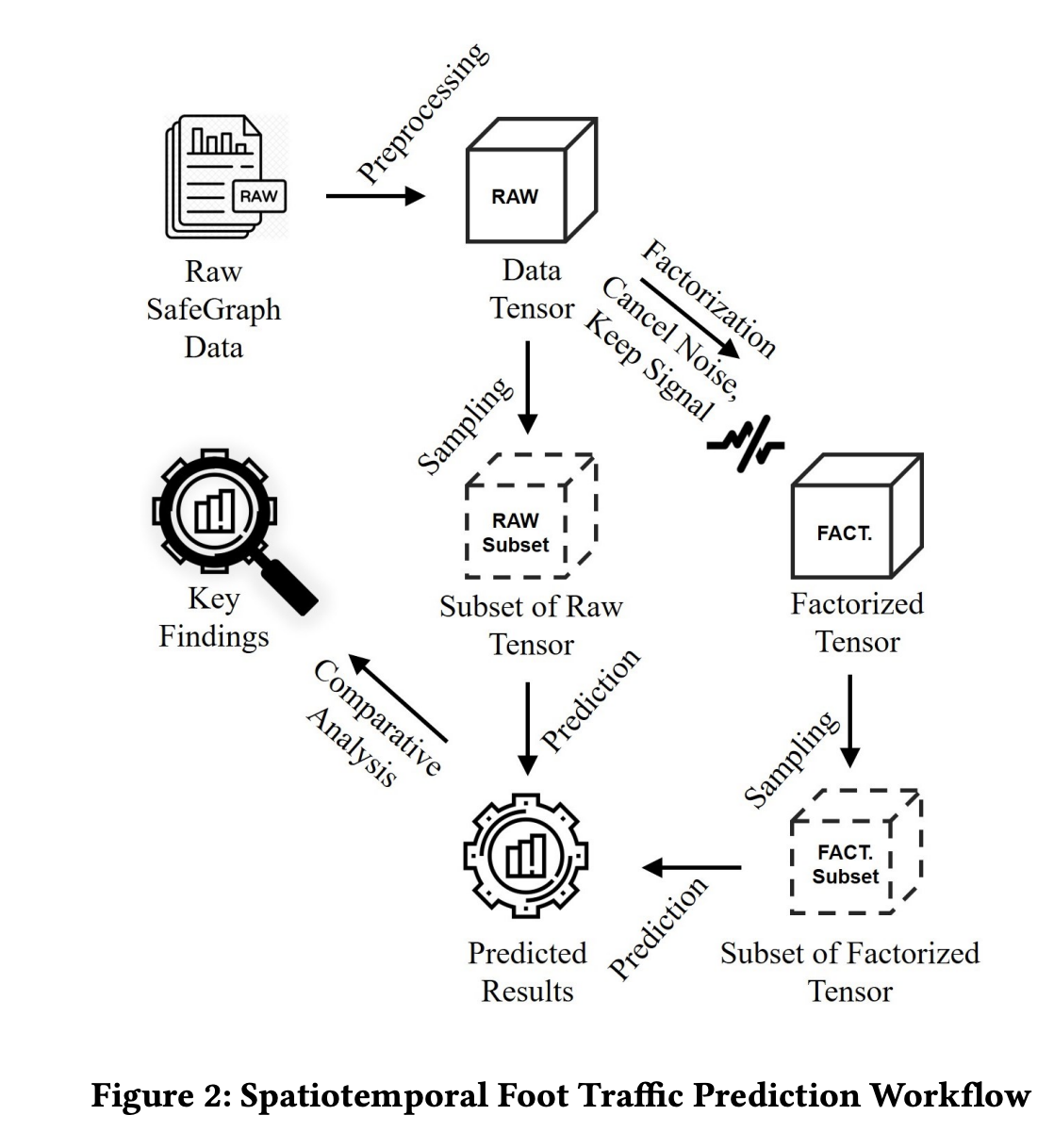
The paper’s experimental results, focused on Fairfax County, Virginia, showed that the tensor factorization approach consistently improved predictions across various scenarios, whether predicting for a single location, a cluster of neighborhoods, or the most popular destinations in the area. We found that prediction accuracy was especially strong when considering higher-traffic POIs. Moving forward, we plan to extend this framework to develop more advanced models that better capture the nuanced and seasonal behaviors of foot traffic.
This paper was presented at the 5th ACM SIGSPATIAL International Workshop on Location-Based Recommendations, Geosocial Networks, and Geoadvertising. The research was conducted as part of STIP 2021.
Paper Reference:
- Spatiotemporal Prediction of Foot Traffic
S. Islam, D. Gandhi, J. Elarde, T. Anderson, A. Roess, T.F. Leslie, H. Kavak, and A. Züfle
5th ACM SIGSPATIAL International Workshop on Location-Based Recommendations, Geosocial Networks, and Geoadvertising, Seattle, Washington, USA (Online), November 2-5, 2021
[Paper] [BibTex]
Funding:
- NSF Award #2030685
- NSF Award #2109647
- George Mason University Office of the Provost and Executive Vice President’s 2021 Summer Team Impact Grant.
Two New Projects
This month marks the start of two new projects in the defense domain. The first project is funded by the Defense Threat Reduction Agency (DTRA) through Applied Research Associates, Inc. focusing on “modeling Human-Infrastructure Interactions Following Nuclear Detonations,” as part of DTRA’s Social Impacts of Nuclear Detonations (SIND) program. The project team includes Dr. William G. Kennedy (PI) and Dr. Hamdi Kavak (Co-PI) from Mason as project leads. Two consultants of this project are Dr. Andrew Crooks at the University at Buffalo, NY and Dr. Christopher Dyer of the University of New Mexico. This three year project will support two graduate students.
![]()
![]()
The second project is called “Detecting Criminal Disruption of Supply Chains”, conducted through George Mason University’s Center for the Investigation of Networked Adaptation (CINA). Serving as a Co-PI, I am part of a team dedicated to identifying and understanding criminal activities that disrupt critical supply chains. This two-year project investigates how illicit networks exploit vulnerabilities in supply chain systems and evaluates intervention strategies to mitigate these threats. By examining real-world disruptions and applying advanced analytical tools, our goal is to enhance resilience and adaptability across various sectors impacted by these criminal networks. The project is funded by the Department of Homeland Security, lead by Dr. Carlotta Carlotta Domeniconi from GMU and Fred Roberts from the Rutgers University. In addition myself, Dr. Sean Luke and Jim Jones serve as GMU Co-PIs. Other collaborators include Dr. Andrew Crooks from the University at Buffalo as well as Drs. Alok Baveja, Weiwei Chen, Dennis Egan, Aman Goswami, Rong Lei, Peter Marsh, Benjamin Melamed, and Viswanath Narayan from Rutgers.
![]()
New Project on Curbing the Spread of Misinformation Campaigns
![]()
I am happy to report that we are starting an exciting project funded by the Commonwealth Cyber Initiative to support research efforts to curb the spread of misinformation and combat disinformation. In particular, we will investigate the research question: “to what extent do the actors in mass media and social media affect each other in creating anti-U.S. perceptions through misinformation and disinformation efforts within the U.S. allies (and thus sowing discord within Western alliances)?” We partnered with Old Dominion University and Tidewater Community College in this effort. More information about this project can be found using this link.
Reusable Synthetic Population and Social Network Data (New Paper!)
It’s no surprise that simulation researchers aim to create realistic urban environments to study population behavior. We have created synthetic population datasets for the larger research community in this work with my Ph.D. student “Richard” Na Jiang and colleagues Andrew Crooks, William Kennedy, and Annetta Burger. More importantly, this synthetic population dataset includes social networks, rarely found in such work. We published this study at the 2021 Annual Modeling and Simulation Conference (ANNSIM’21). Visit the project page /research/simulation-data-analytics-reusable-synthetic-population/ to learn more about this work.
Verification and Validation Framework for COVID-19 Models (New Paper!)
Hundreds of research groups worldwide rushed to create COVID-19 prediction models to enlighten the public and policy-makers. While this is good news for the modeling community, it’s also the time to be more skeptical about results coming from predictive models. In this work with my MS student Maura Lapoff, we created a preliminary verification and validation framework to evaluate COVID-19 forecast models published at the COVID-19 Forecast Hub. We published this study at the 2021 Annual Modeling and Simulation Conference (ANNSIM’21).
Visit the project page /research/verification-and-validation-covid-models/ to learn more about this work.
![]()

