Funded PhD Student Position

We are hiring one Graduate Research Assistant (GRA) to work on a two-year research project to model and simulate attacks on various supply chains. Specifically, the student will employ data- and theory-driven modeling of malicious actors who aim to disrupt supply chain networks. The student will work directly with me and periodically interact with project stakeholders. There will be many opportunities to publish research papers, engage with an interdisciplinary team of scholars, and attend academic conferences.
A successful applicant should/will be a graduate student in the Computational Social Science program and work in the Center for Social Complexity at George Mason University. The other investigators who work in this project are Drs. Sean Luke, Carlotta Domeniconi, and Andrew Crooks.
Expected qualifications:
- Experience in agent-based modeling, preferably in MASON (Java-based open-source framework).
- Implementing social science theories of human behavior in code
- Experience in machine learning
The position is expected to start in the Fall 2021 semester.
The compensation of the position is based on College of Science rates for GRAs including tuition, employment in summers, and student health care coverage. Extension of the position is subject to funding and student performance.
How to Apply:
Send your CV and a paragraph in the form of a cover letter describing your research interests to Dr. Hamdi Kavak (hkavak@gmu.edu).
George Mason University is currently the largest and most diverse university in Virginia with students and faculty from all 50 states and over 135 countries studying in over 200 degree programs at campuses in Arlington, Fairfax and Prince William, as well as at learning locations across the commonwealth. Rooted in Mason’s diversity is a campus culture that is both rewarding and exciting, work that is meaningful, and opportunities to both collaborate and create.
George Mason University is an equal opportunity/affirmative action employer, committed to promoting inclusion and equity in its community. All qualified applicants will receive consideration for employment without regard to race, color, religion, sex, sexual orientation, gender identity, national origin, age, disability or veteran status, or any characteristic protected by law.
Young Simulation Scientist Award
I am honored to announce that the Society for Modeling and Simulation International (SCS) contacted me to notify the delivery of the Young Simulation Award. According to SCS, “[t]his award honors outstanding scientist and engineers under 35 year old who, early in their careers, demonstrated excellence and show potential for leadership at the frontiers of modeling and simulation.” I sincerely thank the SCS award committee for considering me for this prestigious award. Last but not least, I would like to thank my mentors who helped me become who I am today.

Center for Social Complexity Co-Director Position
![]()
I am delighted to announce that I will co-direct the Center for Social Complexity as of May 12, 2021. This is a piece of excellent news for me because I am a long-time follower of this center and its faculty. I have been serving as a member of the center since I joined GMU. With this appointment, I will have the chance to co-direct the center with two great people, Dr. William Kennedy and Dr. Sean Luke. I want to thank them and the former co-director, Dr. Andrew Crooks, for their support and trust.
OSCAR Mentoring Excellence Award
Today I got a fantastic news from the OSCAR office at Mason. I am honored to have received the 2021 OSCAR Mentoring Excellence Award from George Mason University’s Office of Scholarship, Creative Activities, and Research. This award recognizes faculty members who demonstrate exceptional commitment to mentoring undergraduate students in research and fostering a supportive culture of student scholarship at Mason. I am proud to support and guide students in their academic and creative pursuits.

Utilizing Simulation in Cybersecurity (New Paper!)
Cybersecurity threats come in many forms, from data breaches to critical infrastructure attacks. In this paper, we explored the vital role that simulation plays in tackling the fast-evolving cybersecurity landscape, focusing on both present challenges and promising future directions in the literature and practice. This work was conducted in collaboration with my co-authors, including Jose J. Padilla, Daniele Vernon-Bido, Saikou Y. Diallo, Ross Gore, and Sachin Shetty.
We began this work by breaking down cybersecurity into three essential components: targets, threats, and preventive measures shown in figure 1 below. Later, we highlighted five key areas where simulation is making an impact: environment building, testing and evaluation, training exercises, risk assessment, and incorporating human factors into cybersecurity (see figure 2). We then use these two to guide our literature review and categorize cybersecurity simulation research.
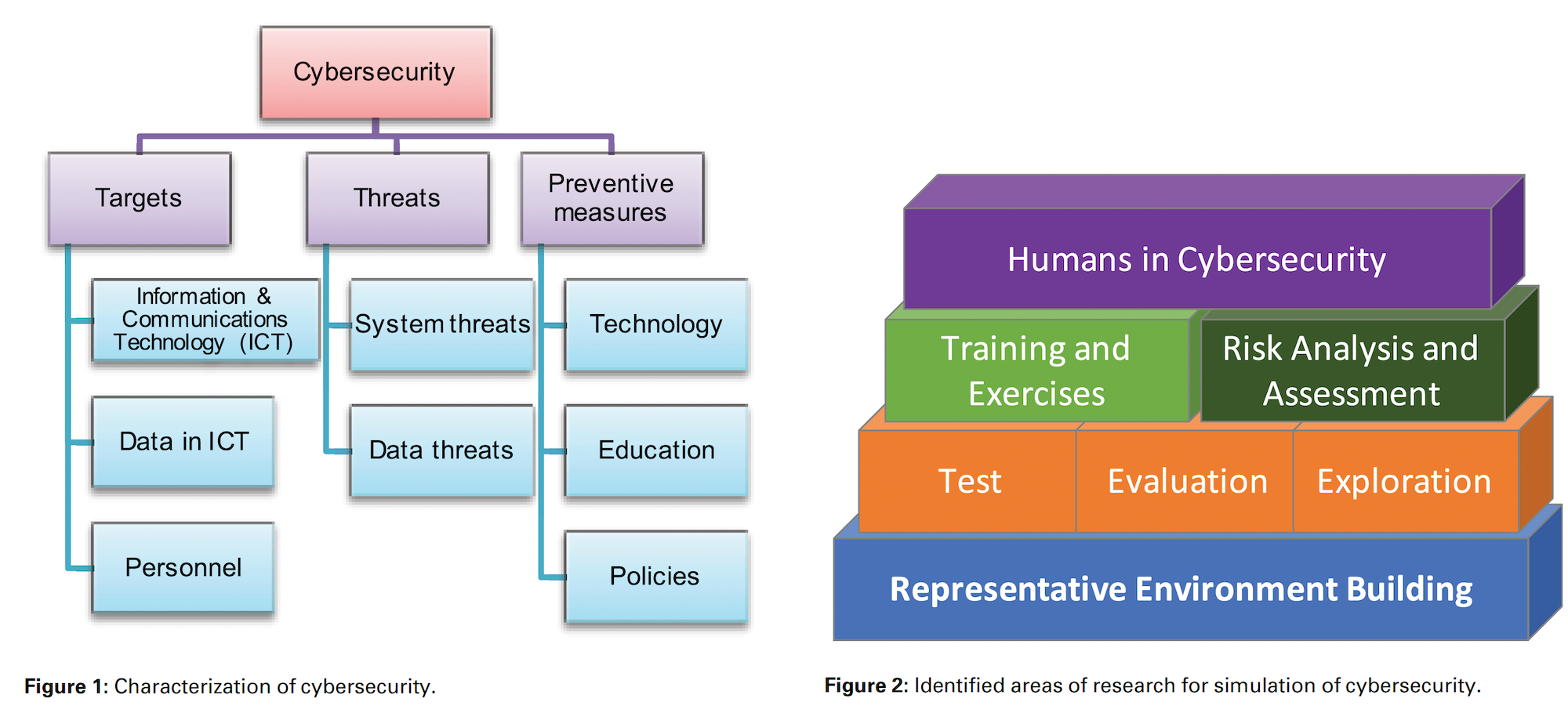
As the outcome of this study, we emphasize the need to include human behavior in cybersecurity simulations, as understanding this element is essential to anticipating and mitigating attacks that rely on social engineering. Looking forward, we call for progress in data collection, the development of new theoretical models, and a deeper focus on behavioral aspects in simulation. These advancements will lead to more robust and realistic simulation environments to secure cyberspace. You can find the open access paper here.
Paid summer research opportunity
I am excited to announce that we are hiring 6 undergraduate and 2 graduate students to work with us for 11 weeks as part of the GMU Summer Team Impact Project (2021). In this period, we will investigate the inclusion of the spatial and temporal variation of human behavior in the spread of COVID-19. Students with a background in one of the following topics are encouraged to apply:
- Data management & processing (especially geographic data)
- Data mining and machine learning
- Agent-based modeling
- Knowledge and interest in respiratory disease dynamics or behavioral psychology
Duration and Compensation:
Students are expected to treat this opportunity as a full-time job for the period of May 31 to August 13, 2021. Undergraduate students will be paid a $4,000 stipend and graduate students will be paid $6,000 across five pay periods in the summer (payment occurs every two weeks).
How to Apply:
Students must submit a cover letter and resume as part of their application. Undergraduate students should apply via the Handshake platform (search for Job ID # 4429299) by March 18, 2021. Graduate students can directly send their application package to Dr. Hamdi Kavak.
Project mentors: Drs. Hamdi Kavak, Taylor Anderson, Andreas Zufle, and Amira Roess

Call for Papers - Annual Modeling and Simulation Conference (ANNSIM) 2021

ANNSIM (Annual Modeling and Simulation Conference) is the new flagship conference of the Society for Modeling and Simulation International (SCS). The new conference is a merger of two previous SCS conferences, namely, SpringSim and SummerSim, and combines many tracks from both conferences. ANNSIM comes with a new track named “Emerging Topics” to solicit studies from recently emerging areas. For this year, the focus of the emerging topics is on pandemic modeling. The complete list of tracks are as follows:
- AI and Simulation (AIS)
- Annual Simulation Symposium (ANSS)
- Communications and Network Simulation (CNS)
- Cyber-Physical Systems (CPS)
- Emerging Topic – Aspects of Pandemic Modeling (ET-APM)
- High Performance Computing and Simulation (HPC)
- Humans, Societies and Artificial Agents (HSAA)
- M&S Based Systems Engineering (MSBSE)
- M&S for Smart Energy Systems (MSSES)
- Modeling and Simulation in Cyber Security (MSCS)
- Modeling and Simulation in Medicine (MSM)
- Theory and Foundations for Modeling and Simulation (TMS)
It is still not too late to submit your paper to ANNSIM. The deadline to submit full papers is March 22, 2021. Note that accepted full papers will be submitted to the ACM and IEEE libraries for archival. Visit the conference web page for more information about submission and tracks.
Based on existing plans, the event will be held hybrid at George Mason University. However, this plan is subject to change if circumstances do not allow in-person part of the conference.
The year 2020 by the numbers

I wanted to start sharing my yearly academic summary for a long time. This is obviously an overdue blog post as we are already in the third month of the new year, but I wanted to start this tradition and continue in the following years. This past year will be a good base comparison point for me moving forward. I have to mention that I got this idea following Aaron Clauset’s blog. In fact, I am using some of his items directly but created different grouping and added some work/life balance measures.
1. Publications
- Peer-reviewed papers published: 4
- Co-authored w/ students: 1 (high school)
- Book chapters (published or accepted): 0
- Other publications: 3
- Papers currently under review: 2
- Papers near completion: 4
- Rejections: 0
- New citations: 103
2. Projects and grant proposals
- Oldest project I still intend to finish: from 2018
- Oldest project completed this year: from 2014
- Fields covered: Modeling and Simulation, Data Science, Computational Social Science
- Number of new collaborators: 7
- Oldest collaborator: from 2011
- External grant proposals submitted (as PI, co-PI, or senior personnel): 6 (totaling $3,296,258)
- Number on which I was PI: 2
- Proposals rejected: 2
- New grants funded: 1
- Proposals pending: 3
- New proposals in the works: 2
- Internal grants received (as PI or co-PI): 1 ($45,000)
3. Service
- Conferences/workshops (co-)organized: 2
- Conferences/workshops attended: 2
- Conference/workshop program committees: 2 new, 6 continuing
- Journals reviewed first time: 4
- Total papers reviewed: 4 for journals, 9 for conferences
- Number of GMU’s graduate program applications reviewed: 92
- Referee requests declined: don’t know maybe 10
- Number of grant review panels I sat on: 0
- Awards received: 1 here
4. Advising
- Students advised: (6 Ph.D., 0 MS, 2 BS, 4 HS)
- Students graduated: 2 Ph.D.
- Thesis/dissertation committees: 6
- Number of recommendation letters written: 13
5. Teaching
- Number of courses taught: (1 new, 2 existing)
- Students enrolled in said courses: 54
- Average teaching evaluation score: 4.92 / 5
6. Communication
Email
- Sent: 10 (≈ 13 / day)
- Received: 12,076 ( ≈ 33 / day)
- Unread emails now: 7
Slack
- Workspaces: 4
- Messages sent: 8844 Homepage
- Unique visitors: 761 for 6 months
- Page hits overall: 7970 for 6 months
- Number of accounts: 1
- Total followers: 312
- Total following: 253
- Number of original tweets: 40
- Number of retweets: 64
- Number of likes: 900+ based on a sample
- Most popular tweet: 6 retweets, 17 likes here
7. How I spent my time (ranking from highest to lowest)
- Teaching (mainly content development)
- Meetings of all kinds
- Writing (mainly proposal and paper)
- Communication (mainly email responses)
- Content reviewing of all kinds
- Housekeeping (planning, logging what I did)
- Brainstorming
- Technical stuff (coding etc.)
8. Work/life balance (based on Fitbit and Toggl data)
- Number of weeks that I worked over 40 hours (excluding coffee breaks etc): 9
- Number of weekends I worked: 45
- Family travel: 2 (COVID hit us)
- Number of weeks that I exercised at least 4 days: 26 (mainly walking)
- Average daily sleep: 5 hours 48 minutes
- Daily sleep records: 2 hours 1 minute (lowest) - 8 hours 40 minutes (highest)
- Fraction of times slept after midnight: 0.91
- Fraction of times slept over 8 hours/day: 0.02 (only 7 days)
- Month that I slept least on average: January (5 hours 26 minutes/day)
- Month that I slept most: November (6 hours 11 minutes/day)
- Number of movies watched: ≈20
- Number of TV shows watched: 1
- Non-technical books read: 1
- Steps this year: 2,812,108 (≈ 7,683/day)
- Total step distance: 2018.81 miles (average of 5.5/day)
Verification and Validation of Models - Invited Lectures Series - 5
The fifth and last invited lecture my Verification and Validation of models course will be on Monday (Nov 16, 2020) at 8:00 PM EST. In this lecture, Dr. Amir Ghasemian, Postdoctoral Research Fellow at Temple University, will give a lecture titled “Limits of model selection and link prediction in complex networks”. If you’re interested in joining the lecture, please email me (see the flyer below) to receive the Zoom invitation link.

Lecture summary:
A common graph mining task is community detection, which seeks an unsupervised decomposition of a network into groups based on statistical regularities in network connectivity. Although many such algorithms exist, community detection’s No Free Lunch theorem implies that no algorithm can be optimal across all inputs. However, little is known in practice about how different algorithms over or underfit to real networks, or how to reliably assess such behavior across algorithms. In first part of my talk, I will present a broad investigation of over and underfitting across 16 state-of-the-art community detection algorithms applied to a novel benchmark corpus of 572 structurally diverse real-world networks. We find that (i) algorithms vary widely in the number and composition of communities they find, given the same input; (ii) algorithms can be clustered into distinct high-level groups based on similarities of their outputs on real-world networks; (iii) algorithmic differences induce wide variation in accuracy on link-based learning tasks; and, (iv) no algorithm is always the best at such tasks across all inputs. Also, we quantify each algorithm’s overall tendency to over or underfit to network data using a theoretically principled diagnostic, and discuss the implications for future advances in community detection.
From (iii) and (iv) one can ask whether different link prediction methods, or families, are capturing the same underlying signatures of “missingness.” For instance, is there a single best method or family for all circumstances? If not, then how does missing link predictability vary across methods and scientific domains (e.g., in social vs. biological networks) or across network scales? Additionally, how close to optimality are current link prediction methods? In the second part of my talk by analyzing 203 link prediction algorithms applied to 550 diverse real-world networks, I will show that no predictor is best or worst overall. I will show combining these many predictors into a single state-of-the-art algorithm achieves nearly optimal performance on both synthetic networks with known optimality and real-world networks. Not all networks are equally predictable, however, and we find that social networks are easiest, while biological and technological networks are hardest.
Verification and Validation of Models - Invited Lectures Series - 4
The fourth invited lecture for the new verification and validation of models course is on Monday (Nov 09, 2020) at 8:00 PM EST. This week, Dr. Philippe Giabbanelli, Associate Professor at Miami University (OH), will give a lecture titled “How to validate subjective perspectives? A computational examination of Fuzzy Cognitive Maps and Agents’ Cognitive Architectures”. If you’re interested in joining the lecture, please email me (see the flyer below) to receive the Zoom invitation link.

Lecture summary:
Humans routinely make decisions under uncertainty and occasionally express contradictory beliefs. This complexity is often lost in an agent-based model, in which modelers equip agents with cognitive architectures that may over-simplify behaviors or lack transparency. The technique of Fuzzy Cognitive Mapping (FCM) allows to externalize the perspectives of a person or group into an aggregate model consisting of a causal map and an inference engine. An FCM may be used as the ‘virtual brain’ of an agent, thus providing rich human behaviors that are transparently acquired from participants. This talk will focus on validating FCMs and hybrid FCM/ABM models.

